Energy-scalable Speech-recognition Circuits
- Category: Circuits & Systems
- Tags: anantha chandrakasan, michael price, speech recognition
Speech recognition is becoming a ubiquitous component of the digital infrastructure, serving as an I/O adapter between people and electronic devices. However, the computational demands imposed by speech recognition make it difficult to integrate into a wide variety of systems. Today’s popular practice of transmitting voice data to cloud servers requires an Internet connection that may impose unwanted complexity, bandwidth, and latency constraints. In order to lift these constraints, we are developing a hardware speech decoder architecture that can easily be scaled to trade among performance (vocabulary, decoding speed, and accuracy), power consumption, and cost.
We are now designing a “baseline” speech recognizer IC to serve as a starting point for architectural studies and improved designs in the future. This chip is intended to decode the 5,000-word Wall Street Journal (Nov. 1992) data set in real time with 10% word error rate (WER) and system power consumption of 100 mW. Building on the architecture of [1] , it performs a Viterbi search over a hidden Markov model using industry-standard weighted finite-state transducer (WFST) transition probabilities [2] and Gaussian mixture model (GMM) emission probabilities. The WFST and GMM parameters are stored in an off-chip NAND flash memory; models for different speakers, vocabularies, and/or languages can be prepared offline and loaded from a computer. The chip integrates the front-end, modeling, and search components needed to convert audio samples from an ADC directly to text without software assistance. Its tradeoffs among energy, speed, and accuracy can be manipulated via the model complexity, runtime parameters (e.g., beam width), and voltage/frequency scaling.
Memory access is expected to be the limiting factor in both decoding speed and power consumption. Previous FPGA implementations required DDR SDRAM with multi-GB/s bandwidth, which is not practical for low-power systems. We are focusing our efforts on minimizing the off-chip memory bandwidth demands using model compression (e.g., nonlinear quantization of parameters [3] ), access reordering, and caching techniques. Future implementations will also allow larger active state list sizes to improve decoding accuracy, especially with larger vocabularies.
-
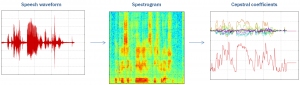
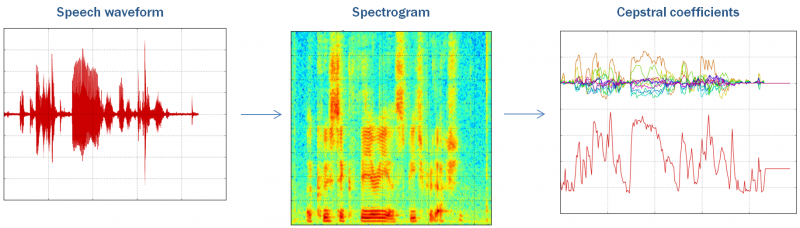
- Figure 1: Signal processing transformations applied in the front-end to generate mel-frequency cepstral coefficients (MFCCs). The audio signal (left) is converted to a spectrogram (center) by a series of short-term FFTs and then to feature vectors (left) via mel-frequency bandpass filters and a DCT for dimensionality reduction.
-
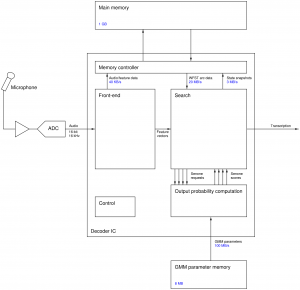
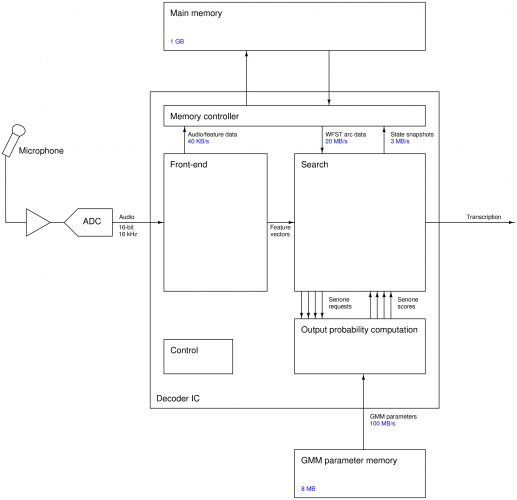
- Figure 2: Block diagram of baseline speech decoder chip and test setup. A second external memory is needed to supply GMM parameters since bandwidth demands exceed the capabilities of NAND flash in the baseline architecture.
- J. Choi, K. You, and W. Sung, “An FPGA implementation of speech recognition with weighted finite state transducers,” in IEEE International Conference on Acoustics Speech and Signal Processing, 2010, pp. 1602-1605. [↩]
- M. Mohri, F. Pereira, and M. Riley, “Speech recognition with weighted finite-state transducers,” in Springer Handbook on Speech Processing and Speech Communication. Heidelberg, Germany: Springer-Verlag, 2008 [↩]
- I. L. Hetherington, “PocketSUMMIT: Small-footprint continuous speech recognition,” in INTERSPEECH, 2007, pp. 1465-1468. [↩]