Approaching the Theoretical Limits of a Mesh NoC with a 16-node Chip Prototype in 45nm SOI CMOS
- Category: Circuits & Systems
- Tags: anantha chandrakasan, li-shiuan peh, sunghyun park
Moore’s law scaling and the diminishing performance returns of complex uniprocessor chips have led to the advent of multicore processors with increasing core counts. Their scalability relies highly on the on-chip communication fabric connecting the cores. An ideal communication fabric would incur only metal-wire delay and energy between the source and destination core. However, there is insufficient wiring for dedicated global point-to-point wires between all cores [1] , and hence, packet-switched Networks-on-Chip (NoCs) with routers that multiplex wires across traffic flows are becoming the de-facto communication fabric in multicore chips [2] .
These routers, however, can impose considerable overhead. In terms of latency, each router can take several pipeline stages to perform the control decisions necessary to regulate the sharing of wires across multiple flows. Inefficiency in the control also frequently leads to poor link utilization on NoCs. Buffers queues have been used to improve flow control and link utilization, but they come with overhead in energy consumption. The conventional wisdom is that NoC design involves trading off latency, bandwidth, and energy.
In this work, we present a case study of our chip prototype of a 16-node 4×4 mesh NoC fabricated in 45nm SOI CMOS that aims to simultaneously optimize energy-latency-throughput for unicasts, multicasts, and broadcasts. We first define and analyze the theoretical limits of a mesh NoC in latency, throughput, and energy and then describe how we approach these limits through a combination of microarchitecture and circuit techniques. Our 1.1V 1GHz NoC chip achieves 1-cycle router-and-link latency at each hop and energy-efficient router-level multicast support, delivering 892Gb/s (87.1% of the theoretical bandwidth limit) at 531.4mW for a mixed traffic of unicasts and broadcasts. Through this fabrication, we derive insights that help guide our research and, we believe, will also be useful to the NoC and multicore research community.
-
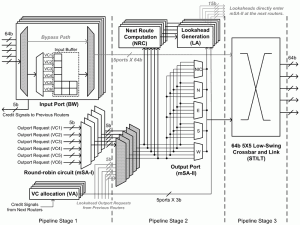
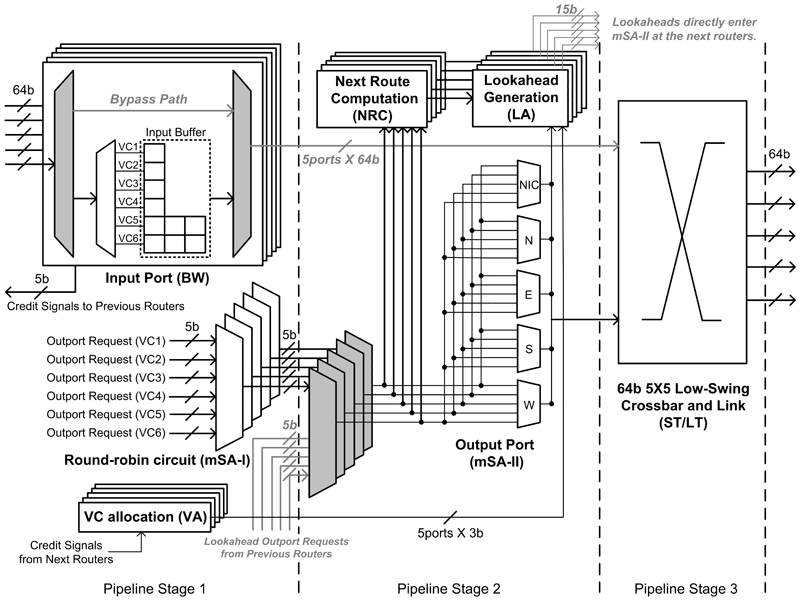
- Figure 1: Proposed router microarchitecture that enables multicast virtual bypassing by lookaheads. If the lookaheads succeed in the crossbar pre-allocation at the next node, actual flits can bypass the first pipeline stages, resulting in no buffering energy and 1-cycle per-hop latency.
-
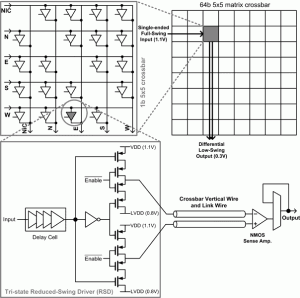
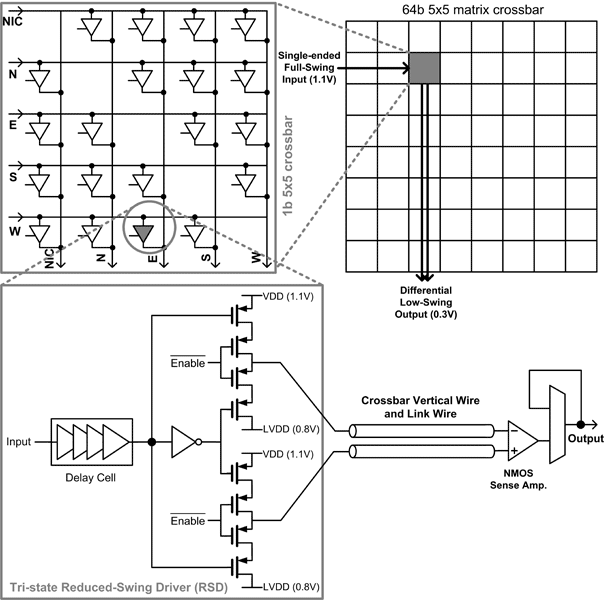
- Figure 2: Proposed tri-stated low-swing crossbar switch where low-swing signaling can be integrated into not only links but also crossbar vertical wires, which also have significant parasitic capacitance.
- S. Heo and K. Asanovic, “Replacing global wires with an on-chip network: A power analysis,” IEEE International Symposium on Low Power Electronics and Design, 2005, pp. 369-374. [↩]
- W. J. Dally and B. Towles, “Route packets not wires: On-chip interconnection networks,” ACM/IEEE Design Automation Conference, pp. 684-689, 2001. [↩]