A Broadcast-optimized, Low-Swing Signaling-based On-Chip Network in 45nm SOI CMOS
- Category: Circuits & Systems
- Tags: Anantha Chandrakasan, Li-Shiuan Peh, Sunghyun Park
Designing on-chip networks optimized for a cache coherence protocol is critical for many-core processors to achieve peak efficiency in energy, latency, and throughput performance. Considering that advanced cache coherence protocols [1] [2] [3] count on a combination of multicasts, broadcasts, and direct requests, it is essential to optimize on-chip networks for one-to-many multicasts and broadcasts. In addition, since such bandwidth-hungry on-chip networks consume substantial energy in their data path, energy-efficient crossbar switches and links are required.
This work presents broadcast-optimized, low-swing signaling-based on-chip networks. The proposed on-chip networks feature (1) multicast buffer bypassing flow control, (2) a broadcast-optimized crossbar switch, and (3) low-swing signaling in the data path. The multicast bypassing scheme generates multiple lookahead signals, one corresponding to each output port out of which the flit forks. To maximize bypassing efficiency, output port requests of the incoming lookahead signals are prioritized over the requests of other flits buffered at the same input port. When the lookahead wins all of its output ports, the intermediate router sets up the bypass control signals that allow the flit to connect directly to the crossbar and link, instead of getting buffered. For the broadcast-optimized crossbar switch and low-swing signaling in the data path, a tri-state RSD-based crossbar is presented. The proposed low-swing crossbar features (1) an inherent power gating circuit, (2) higher bandwidth driven by linear-mode RSD, (3) a longer low-swing signaling data path from cross points to link RXs, (4) SOI-friendly circuit design, and (5) potential to be integrated into the CAD synthesis flow.
-
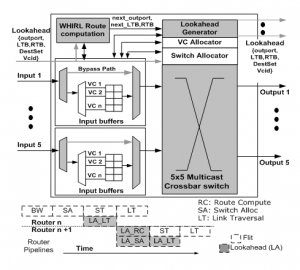
- Figure 1: Proposed router microarchitecture that enables a multicast buffer bypassing flow control. It supports partially successful allocation by the lookahead, in which case the incoming flit simultaneously uses the bypass path and gets buffered simultaneously.

-
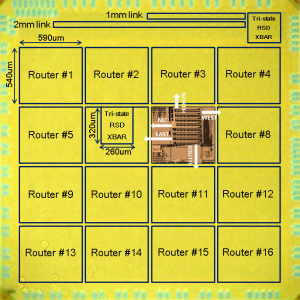
- Figure 2: Broadcast-optimized, low-swing signaling-based on-chip networks with 16 routers connected in a mesh topology. Traffic generators allow varying activity at all routers to explore energy measurements.

- N. Agarwal, L.-S. Peh, and N. K. Jha, “In-network coherence filtering: snoopy coherence without broadcast,” IEEE/ACM International Symposium on Microarchitecture (MICRO), no. 42, pp.232-243, 2009. [↩]
- P. Conway, N. Kalyanasundharam, G. Donley, K. Lepak, and B. Hughes, “Cache hierarchy and memory subsystem of the AMD Opteron processor,” IEEE/ACM International Symposium on Microarchitecture (MICRO), no. 30, pp. 16-29, 2010. [↩]
- E. E. Bilir, R. M. Dickson, Y. Hu, M. Plakal, D. J. Sorin, M. D. Hill, and D. A. Wood, “Multicast snooping: A coherence method using a multicast address network,” IEEE/ACM International Symposium on Computer Architecture (ISCA), pp. 294-304, 1999. [↩]