
|
Department of Electrical Engineering and Computer Science Department of Mechanical Engineering |
| 6.050J / 2.110J Information and Entropy |
|
|
The basic building block of your body is a cell. Two or more groups of cells form tissues, such as bone or muscle; tissues organize to form organs, such as the heart or brain; organs form organ systems, such as the circulatory system or nervous system; the organ systems together form you, the organism. Cells can be classified as either eukaryote or prokaryote cells -- with or without a nucleus, respectively. The cells that make up your body and those of all animals, plants, and fungi are eukaryotic. Prokaryotes are bacteria and cyanobacteria.
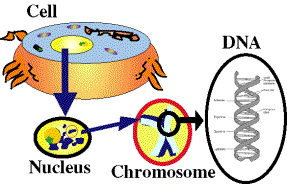 The nucleus forms a separate compartment from the rest of the cell body;
this compartment serves as the central storage center for all the hereditary
information of the
eukaryote cells. All of the genetic information that forms the book
of life is stored on individual chromosomes found within the nucleus. In
healthy humans there are 23 pairs of chromosomes (46 total). Each
one of the chromosomes contains one threadlike deoxyribonucleic acid (DNA)
molecule. Genes are the functional regions along these DNA strands,
which are the fundamental physical units that carry hereditary information
from one generation to the next. In the prokaryotes the chromosomes
are free floating in the cell body since there is no nucleus.
The nucleus forms a separate compartment from the rest of the cell body;
this compartment serves as the central storage center for all the hereditary
information of the
eukaryote cells. All of the genetic information that forms the book
of life is stored on individual chromosomes found within the nucleus. In
healthy humans there are 23 pairs of chromosomes (46 total). Each
one of the chromosomes contains one threadlike deoxyribonucleic acid (DNA)
molecule. Genes are the functional regions along these DNA strands,
which are the fundamental physical units that carry hereditary information
from one generation to the next. In the prokaryotes the chromosomes
are free floating in the cell body since there is no nucleus.
The DNA molecules are composed of two interconnected chains of nucleotides
that form one DNA strand. Each nucleotide is composed of a
sugar, phosphate,
and one of four bases. The bases are adenine, guanine, cytosine,
and thymine. For convenience the nucleotides are referenced by their
base pairs; instead of saying deoxyguanosine monophosphate we would
simply say guanine (or G) when referring to the individual nucleotide.
Thus we could write CCACCA to indicate a chain of interconnected cytosine-cytosine-adenine-
cytosine-cytosine-adenine nucleotides.
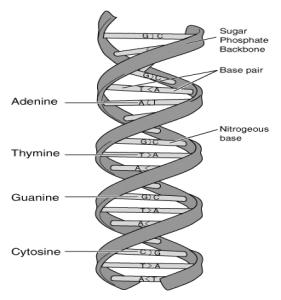
The individual nucleotide chains are interconnected through the pairing of their nucleotide bases into a single double helix structure. The rules for pairing are: cytosine always pairs with guanine and thymine always pairs with adenine. These DNA chains are replicated during somatic (all cells except those destined to be sex cells) cell division and the complete genetic information is passed on to the resulting cells.
Genes are part of the chromosomes and coded for on the DNA strands. Individual functional sections of the threadlike DNA are called genes. The information encoded in genes directs the maintenance and development of the cell and organism. This information travels a path from the input to the output: DNA (genes) => mRNA => ribosome/tRNA => Protein. In essence the protein is the final output that is generated from the genes, such that the genes are blueprints for the individual proteins. The proteins themselves can be structural components of your body (such as muscle fibers) or functional components (enzymes that help regulate thousands of biochemical processes in your body). Proteins are built from polypeptide chains, which are just strings of amino acids (a single polypeptide chain constitutes a protein, but often functional proteins are composed of multiple polytpeptide chains).
The genetic message is communicated from the cell nucleus's DNA to ribosomes outside the nucleus via messenger RNA (ribosomes are cell components that help in the eventual construction of the final protein). Transcription is the process in which messenger RNA is generated from the DNA. The messenger RNA is a copy of a section of a single nucleotide chain. It is a single strand, exactly like DNA except for differences in the nucleotide sugar and that the base thymine is replaced by uracil. Messenger RNA forms by the same base pairing rule as DNA except T is replaced by U- (C to G, U to A).
This messenger RNA
![]() is
translated in the cell body, with the help of ribosomes and tRNA, into
a string of amino acids (a protein). The ribosome
is
translated in the cell body, with the help of ribosomes and tRNA, into
a string of amino acids (a protein). The ribosome
![]() holds the messenger RNA in place and the transfer RNA
holds the messenger RNA in place and the transfer RNA
![]() places the appropriate amino acid
places the appropriate amino acid
 into the forming protein.
into the forming protein.
The messenger RNA is translated into a protein by first docking with a ribosome. An initiator tRNA binds to the ribosome at a point corresponding to a start codon on the mRNA strand -- in humans this corresponds to the AUG codon. This tRNA molecule carries the appropriate amino acid called for by the codon and matches up at with the mRNA chain at another location along its nucleotide chain called an anticodon. The bonds form via the same base pairing rule for mRNA and DNA(there are some pairing exceptions that will be ignored for simplicity). Then a second tRNA molecule will dock on the ribosome of the neighboring location indicated by the next codon. It will also be carrying the corresponding amino acid that the codon calls for. Once both tRNA molecules are docked on the ribosome the amino acids that they are carrying bond together. The initial tRNA molecule will detach leaving behind its amino acid on a now growing chain of amino acids. Then the ribosome will shift over one location on the mRNA strand to make room for another tRNA molecule to dock with another amino acid. This process will continue until a stop codon is read on the mRNA, in humans the termination factors are UAG, UAA, and UGA. When the stop codon is read the chain of amino acids (protein) will be released from the ribosome structure.
![]()
What are amino acids? They are organic compounds with a central carbon atom, to which is attached by covalent bonds
The side chains range in complexity from a single hydrogen atom (for the amino acid glycine), to structures incorporating as many as 18 atoms (arginine). Thus each amino acid consists of between 10 and 27 atoms. Exactly twenty different amino acids (sometimes called the "common amino acids") are used in the production of proteins as described above. Ten of these are considered "essential" because they are not manufactured in the human body and therefore must be acquired through eating (arginine is essential for infants and growing children). Nine amino acids are hydrophilic (water-soluble) and eight are hydrophobic (the other three are called "special"). Of the hydrophilic amino acids, two have net negative charge in their side chains and are therefore acidic, three have a net positive charge and are therefore basic; and four have uncharged side chains. Usually the side chains consist entirely of hydrogen, nitrogen, carbon, and oxygen atoms, although two (cysteine and methionine) have sulfur as well.
There are twenty different common amino acids that need to be coded for and only four different bases. How is this done? As single entities the nucleotides (A,C,T, or G) could only code for four amino acids, obviously not enough. As pairs they could code for 16 (42) amino acids, again not enough. With triplets we could code for 64 (43) possible amino acids -- this is the way it is actually done in the body, and the string of three nucleotides together is called a codon. Why is this done? How has evolution developed such an inefficient code with so much redundancy? There are multiple codons for a single amino acid for two main biological reasons: multiple tRNA species exist with different anti codons to bring certain amino acids to the ribosome, and errors/sloppy pairing can occur during translation (this is called wobble).
Codons, strings of three nucleotides, thus code for amino acids. Below is the genetic code, from the messenger RNA codon to amino acid:
| mRNA | Second nucleotide base of mRNA codon | ||||
| First nucleotide base of mRNA codon |
U | C | A | G | |
| U | UUU = Phe
UUC = Phe UUA = Leu UUG = Leu |
UC* = Ser | UAU = Tyr
UAC = Tyr UAA = stop UAG = stop |
UGU = Cys
UGC = Cys UGA = stop UGG = Trp |
|
| C | CU* = Leu | CC* = Pro | CAU = His
CAC = His CAA = Gln CAG = Gln |
CG* = Arg | |
| A | AUU = Ile
AUC = Ile AUA = Ile AUG = Met (start) |
AC* = Thr | AAU = Asn
AAC = Asn AAA = Lys AAG = Lys |
AGU = Ser
AGC = Ser AGA = Arg AGG = Arg |
|
| G | GU* = Val | GC* = Ala | GAU = Asp
GAC = Asp GAA = Glu GAG = Glu |
GG* = Gly | |
Here and in the chart below * stands for (U, C, A, or G); thus CU* could be either CUU, CUC, CUA, or CUG
The three-letter abbreviations for the amino acids are as follows (also shown are the one-letter abbreviation for each, its molecular weight, and some of its properties, taken from H. Lodish, D. Baltimore, A. Berk, S. L. Zipursky, P. Matsudaira, and J. Darnell, "Molecular Cell Biology," third edition, W. H. Freeman and Company, New York, NY; 1995):
| Symbols | Amino Acid | M Wt | Properties | Codon(s) | ||
| Ala | A | Alanine | 89.09 | Non-essential | Hydrophobic | GC* |
| Arg | R | Arginine | 174.20 | Essential | Hydrophilic, basic | CG* AGA AGG |
| Asn | N | Asparagine | 132.12 | Non-essential | Hydrophilic, uncharged | AAU AAC |
| Asp | D | Aspartic Acid | 133.10 | Non-essential | Hydrophilic, acidic | GAU GAC |
| Cys | C | Cysteine | 121.15 | Non-essential | Special | UGU UGC |
| Gln | Q | Glutamine | 146.15 | Non-essential | Hydrophilic, uncharged | CAA CAG |
| Glu | E | Glutamic Acid | 147.13 | Non-essential | Hydrophilic, acidic | GAA GAG |
| Gly | G | Glycine | 75.07 | Non-essential | Special | GG* |
| His | H | Histidine | 155.16 | Essential | Hydrophilic, basic | CAU CAC |
| Ile | I | Isoleucine | 131.17 | Essential | Hydrophobic | AUU AUC AUA |
| Leu | L | Leucine | 131.17 | Essential | Hydrophobic | UUA UUG CU* |
| Lys | K | Lysine | 146.19 | Essential | Hydrophilic, basic | AAA AAG |
| Met | M | Methionine | 149.21 | Essential | Hydrophobic | AUG |
| Phe | F | Phenylalanine | 165.19 | Essential | Hydrophobic | UUU UUC |
| Pro | P | Proline | 115.13 | Non-essential | Special | CC* |
| Ser | S | Serine | 105.09 | Non-essential | Hydrophilic, uncharged | UC* AGU AGC |
| Thr | T | Threonine | 119.12 | Essential | Hydrophilic, uncharged | AC* |
| Trp | W | Tryptophan | 204.23 | Essential | Hydrophobic | UGG |
| Tyr | Y | Tyrosine | 181.19 | Non-essential | Hydrophobic | UAU UAC |
| Val | V | Valine | 117.15 | Essential | Hydrophobic | GU* |
| start | Methionine | AUG | ||||
| stop | UAA UAG UGA | |||||